No Training Animal Detection Using Vision Language Model
Ananimal detection system powered by Vision-Language Models. Uses GroundingDINO for open-vocabulary object detection and LLaVA for refined classification.
Project Overview
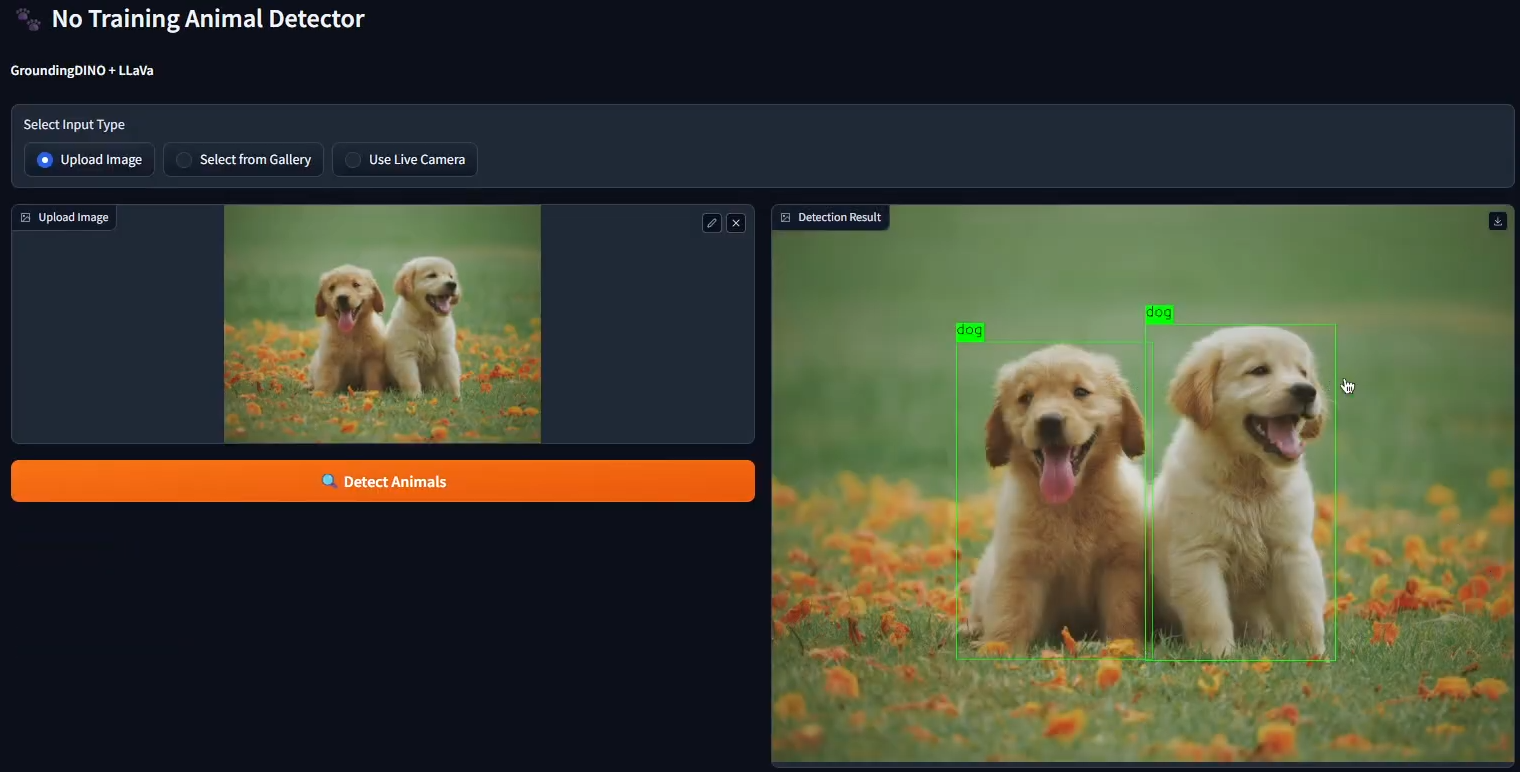
This project introduces a 'zero-shot' approach to wildlife monitoring, allowing users to detect and identify animals in images without any prior training on specific species datasets.
The pipeline integrates GroundingDINO to locate objects based on text prompts (e.g., 'animal') and then passes cropped detections to LLaVA (Large Language-and-Vision Assistant) for refined classification and descriptive analysis.
Designed for flexibility and rapid deployment, the system can adapt to new environments and rare species instantly by simply modifying the text prompts, bypassing the traditional bottlenecks of computer vision workflows.
Key Features
- Zero-shot animal detection using open-vocabulary GroundingDINO
- Refined species classification and behavioral description via LLaVA
- Automated image cropping and preprocessing for multi-stage analysis
- Support for diverse environments (forest, urban, domestic) without retraining
- Visual bounding box annotation
Technologies Used
Project Details
Client
Personal Project
Timeline
2025
Role
Solo Project


© 2026 Oahed Noor Forhad. All rights reserved.